<---- Back to main parsers page
page parsers
We can now produce individual rows of rich metadata. To arrange them all into a useful structure, we will use Page Parsers.
The Page Parser is the top level parsing object. It takes a single document and produces a list--or a list of lists--of metadata. Here's the main UI:
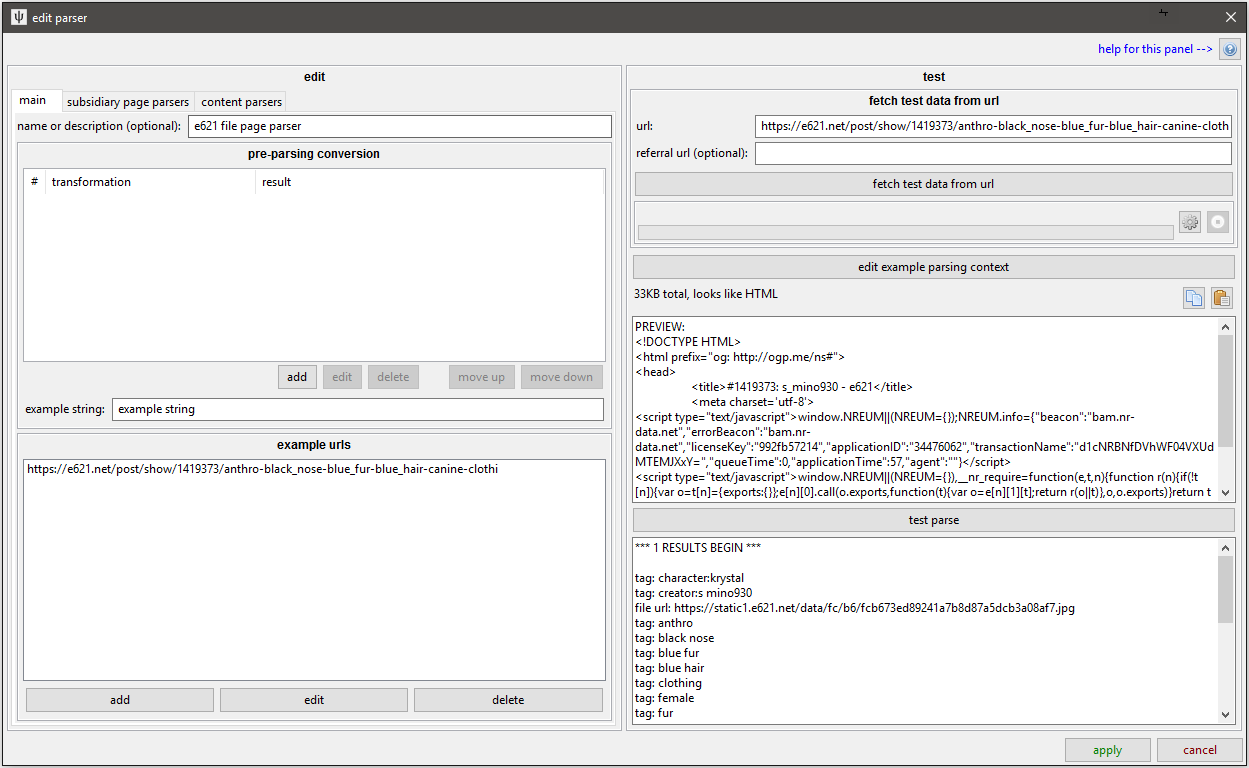
Notice that the edit panel has three sub-pages.
main
- Name: Like for content parsers, I recommend you add good names for your parsers.
- Pre-parsing conversion: If your API source encodes or wraps the data you want to parse, you can do some string transformations here. You won't need to use this very often, but if your source gives the JSON wrapped in javascript (like the old tumblr API), it can be invaluable.
- Example URLs: Here you should add a list of example URLs the parser works for. This lets the client automatically link this parser up with URL classes for you and any users you share the parser with.
content parsers
This page is just a simple list:
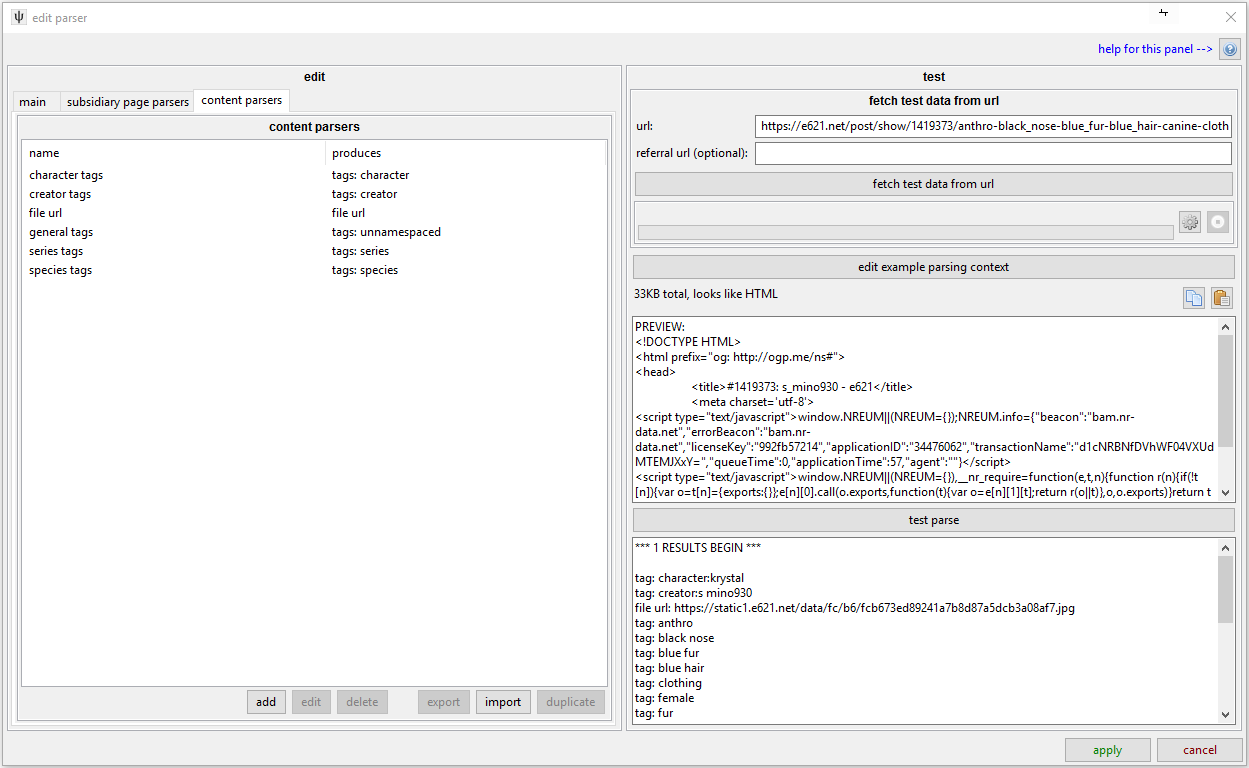
Each content parser here will be applied to the document and returned in this page parser's results list. Like most boorus, e621's File Pages only ever present one file, and they have simple markup, so the solution here was simple. The full contents of that test window are:
*** 1 RESULTS BEGIN *** tag: character:krystal tag: creator:s mino930 file url: https://static1.e621.net/data/fc/b6/fcb673ed89241a7b8d87a5dcb3a08af7.jpg tag: anthro tag: black nose tag: blue fur tag: blue hair tag: clothing tag: female tag: fur tag: green eyes tag: hair tag: hair ornament tag: jewelry tag: short hair tag: solo tag: video games tag: white fur tag: series:nintendo tag: series:star fox tag: species:canine tag: species:fox tag: species:mammal *** RESULTS END ***
When the client sees this in a downloader context, it will where to download the file and which tags to associate with it based on what the user has chosen in their 'tag import options'.
subsidiary page parsers
But what if you have multiple files per page? What sort of shape of parsing would you need? You might be able to get away with a single content parser for a simple gallery page, where you could just find n thumbnail links, but what if you want to pull some other metadata for each thumbnail (like a title or ratings tag) at the same time? What if you are parsing an imageboard thread, where each file's links and filename tags and source times are all on just the one page? It is easy to find such a page's tags and URLs, but not so easy to group the correct rows together.
The solution is to split the file up into smaller 'posts' and to parse each in turn with a subsidiary page parsers:

talk about get html/json in the formula, show the new fourth tab and delve into that. show how splitting the html of an example html thread parser goes
Each subsidiary page parser will produce 0-n file results (typically for a Gallery or Watchable URL).
mention vetos again